
In the previous post, we discussed the executable header and the section header. Now we are familiar with the structure of the section header, let’s discuss the sections and the program header in this post.
3. Sections
Sections are basically classified into two parts, data, and code. Where the data section contains variables and program data, these sections are writable but the code section only contains instruction bits, so it is marked as nonwritable to avoid any kind of vulnerability attack. The below image specifies the sections found in a "Hello World" program ELF binary compiled by gcc version 4.8.5.
 |
| List of sections in an executable ELF |
The readelf output shows the relevant basic information of each section, including the index (in the section header table), name, and type, virtual address, file offset, and size in bytes of the section. For sections containing a table (such as symbol tables and relocation tables), there’s also a column showing the size of each table entry. Finally, readelf also shows the relevant flags for each section, as well as the index of the linked section (if any), additional information specific to the section type, and alignment requirements. Here we will only cover some important sections instead of all.
The .init and .fini Sections
The .init section (index 11) contains executable code that performs initialization tasks and needs to run before transferring control to the main entry point of the binary. Thus, if you’re familiar with object-oriented programming, you can think of this section as a constructor. The .fini section (index 14) is analogous to the .init section, except that it runs after the main program completes, essentially functioning as a kind of destructor.
The .text Section
The .text section (index 13) is where the main code of the program resides. The .text section has the type SHT_PROGBITS because it contains user-defined code and also the section flags indicate that the section is executable but not writable.
In general, executable sections should almost never be writable (and vice versa) because it would make it easier for an attacker to exploit the vulnerability to modify the program's behavior by directly overwriting the code.
Besides the application-specific code, the .text section contains a number of standard functions that perform initialization and finalization tasks, such as _start, register_tm_clones, and frame_dummy. For now, Let's see how control goes to the main from _start function.
 |
| Part of .text section |
When you write a C program, there’s always the main function where your program begins. But if you inspect the entry point of the binary(you can refer to the output of readelf -h a.out from PART 2), you’ll find that it doesn’t point to main at address 0x40052d. Instead, it points to address 0x400440, the beginning of _start. So, how does execution eventually reach the main?
 |
| Start of .text section |
If you look closely at the _start function it contains an instruction at address 0x40045d which moves the address of main into the rdi register, which is used to pass parameters to function calls on x64 platforms. Then, _start calls a function called __libc_start_main. It resides in the .plt section, which is part of a shared library. The function __libc_start_main finally calls the address of the main to begin the execution of user-defined code.
The .bss, .data, and .rodata Sections
Since code sections are generally not writable, the variables are placed in one or more dedicated sections, which are writable. Constant data is usually also kept in its own section to keep the binary neatly organized. This can make clear which bytes represent instructions and which represent data.
The not writable .rodata section, which stands for “read-only data,” is dedicated to storing constant values. The default values of initialized variables are stored in the .data section, which is marked as writable since the values of variables may change at runtime.
Finally, the writable .bss section stands for “block started by symbol” reserves space for uninitialized variables. The .bss section has type SHT_NOBITS unlike .rodata and .data, which have type SHT_PROGBITS. This is because .bss doesn’t occupy any bytes in the binary as it exists on disk, it’s simply a directive to allocate a block of memory for uninitialized variables when setting up an execution environment for the binary. Typically, variables that live in .bss are zero-initialized.
The .plt, .got, and .got.plt Sections and lazy binding
The .plt(Procedure Linkage Table) is a code section that contains executable code, just like .text, while .got(Global Offset Table) is a data section. ELF binaries often contain a separate GOT section called .got.plt for use in conjunction with .plt in the lazy binding process.
 |
| Dynamically Resolving a Library Function Using the PLT |
 |
| Dynamic section |
Tags of type DT_NEEDED inform the dynamic linker about the dependencies of the executable. For instance, the binary uses the puts function from the libc.so.6 shared library, so it needs to be loaded when executing the binary. the .dynamic section also contains pointers to other important information required by the dynamic linker (for instance, the dynamic string table, dynamic symbol table, .got.plt section, and dynamic relocation section pointed to by tags of type DT_STRTAB, DT_SYMTAB, DT_PLTGOT, and DT_RELA, respectively). The DT_VERNEED and DT_VERNEEDNUM tags specify the starting address.
The .init_array and .fini_array Sections
The .init_array is a data section that can contain as many function pointers used as constructors. Each of these functions is called when the binary is initialized before the main is called. In GCC, you can mark functions in your C source files as constructors by declaring them with __attribute__((constructor)). The .fini_array contains pointers to destructors rather than constructors. The pointers contained in .init_array and .fini_array can be changed to modify its behavior. Binaries produced by older GCC versions may contain sections called .ctors and .dtors instead of .init_array and .fini_array.
The .shstrtab, .symtab, .strtab, .dynsym, and .dynstr Sections
The .shstrtab section contains the names of all the sections in the binary to allow tools like readelf to find out the names of the sections. The .symtab section is the main symbol table used in compile-time linking or runtime debugging. The symbol names (as NULL-terminated strings) are stored in .strtab section. .dynsym and .dynstr sections are analogous to .symtab and .strtab, except that they contain symbols and strings needed for dynamic linking rather than static linking. Command "readelf --wide --syms a.out" can be used to see the static and dynamic symbol strings.
4. Program Headers
The Program Headers are used during execution (ELF's "execution view"), as opposed to the section view provided by the section header table. It tells the kernel or the runtime linker what to load into virtual memory and how to find dynamic linking information.
 |
| Program header structure |
The p_type Field
The p_type field identifies the type of the segment. Important values for this field include PT_LOAD, PT_DYNAMIC, and PT_INTERP. Segments of type PT_LOAD, as the name implies, are intended to be loaded into memory when setting up the process. The size of the loadable chunk and the address to load it at are described in the rest of the program header. As you can see in the readelf output, there are usually at least two PT_LOAD segments—one encompassing the nonwritable sections and one containing the writable data sections. The PT_INTERP segment contains the .interp section, which provides the name of the interpreter that is to be used to load the binary. In turn, the PT_DYNAMIC segment contains the .dynamic section, which tells the interpreter how to parse and prepare the binary for execution. It’s also worth mentioning the PT_PHDR segment, which encompasses the program header table.
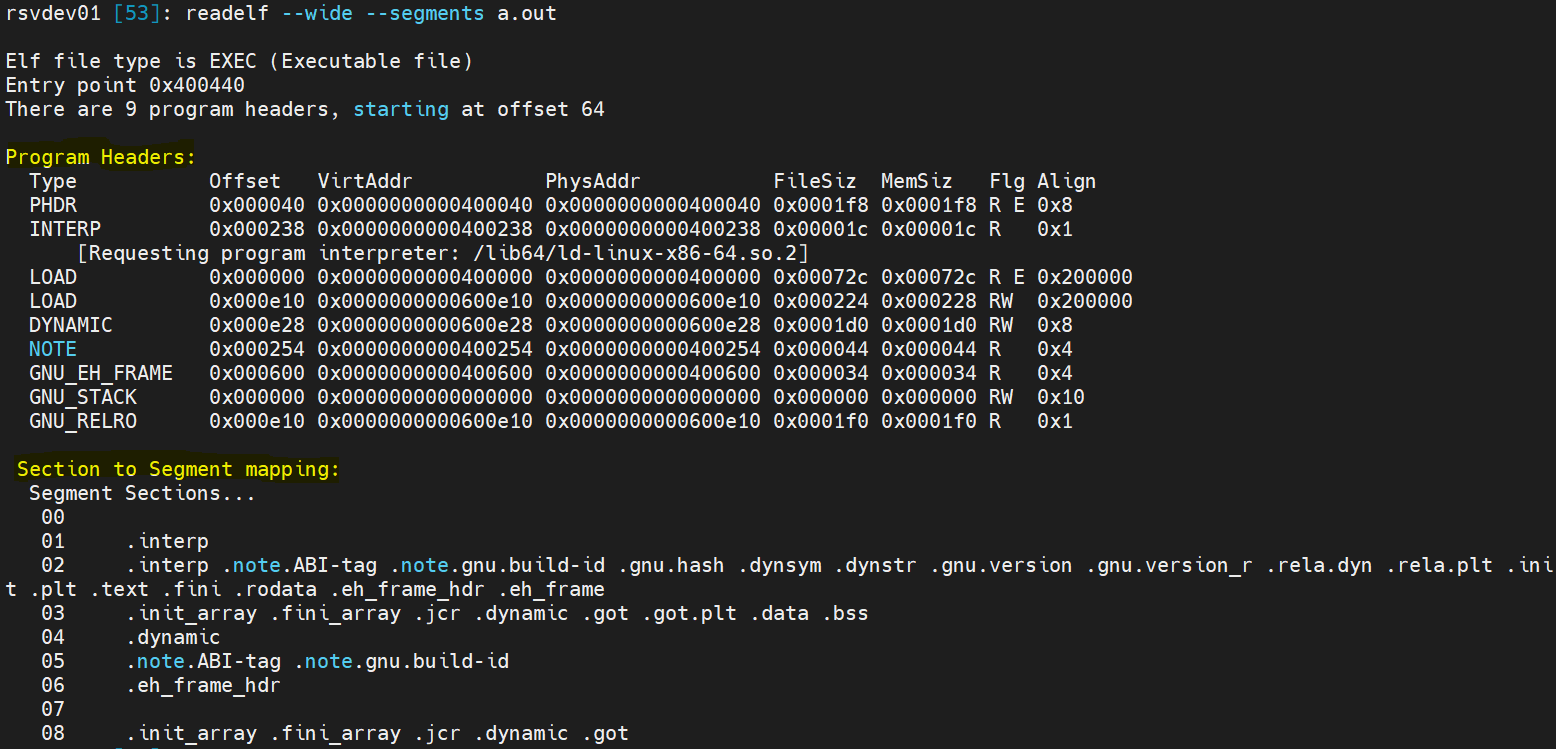 |
| Program headers and the segment map view |
The p_flags Field
The flags specify the runtime access permissions for the segment. Three important types of flags exist: PF_X, PF_W, and PF_R to specify the segments are executable, writable, and readable respectively.
The p_offset, p_vaddr, p_paddr, p_filesz, and p_memsz Fields
The p_offset, p_vaddr, and p_filesz fields specify the file offset at which the segment starts, the virtual address at which it is to be loaded, and the file size of the segment, respectively. most of the cases p_filesz and p_memsz are the same*.
The p_align Field
The p_align field indicates the required memory alignment (in bytes) for the segment.




{kind=link}