
Pipelining means dividing the process of instruction into an independent section and overlap them to get better performance. And the 3 stage Pipelining defines fetch-decode-execute. First, fetch the instruction, then decode the instruction, third execute that instruction. this is the complete process.
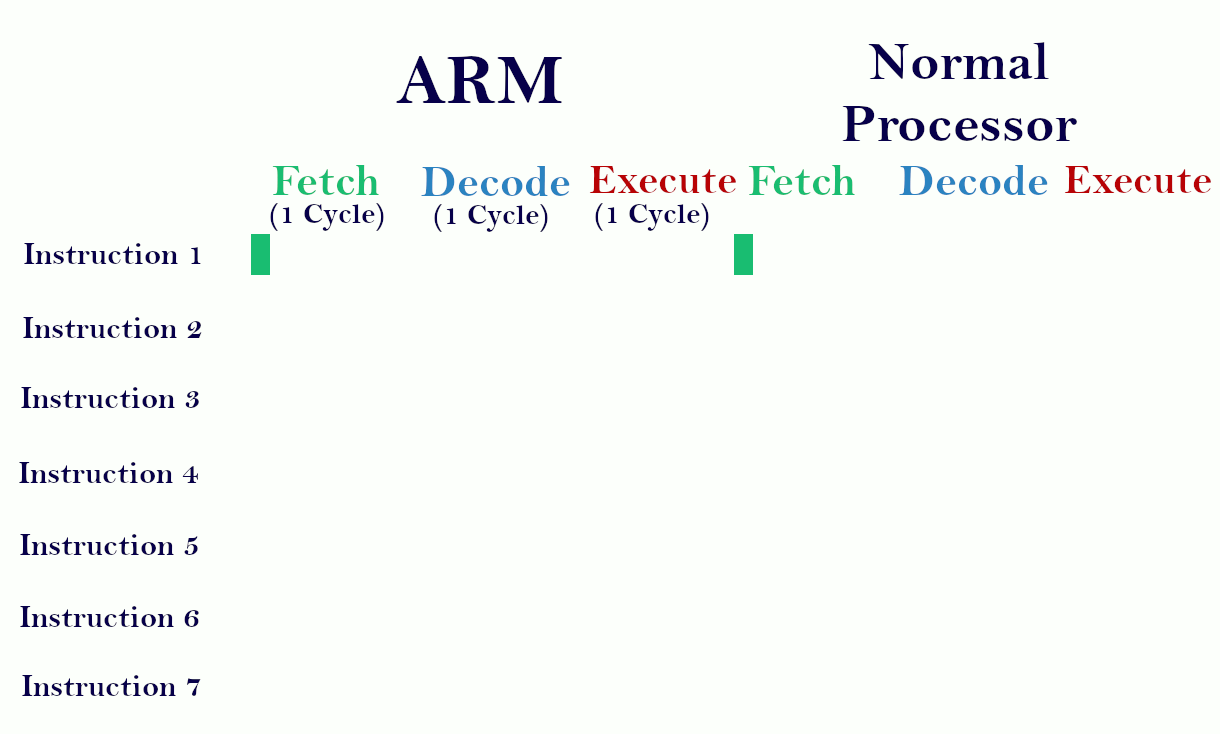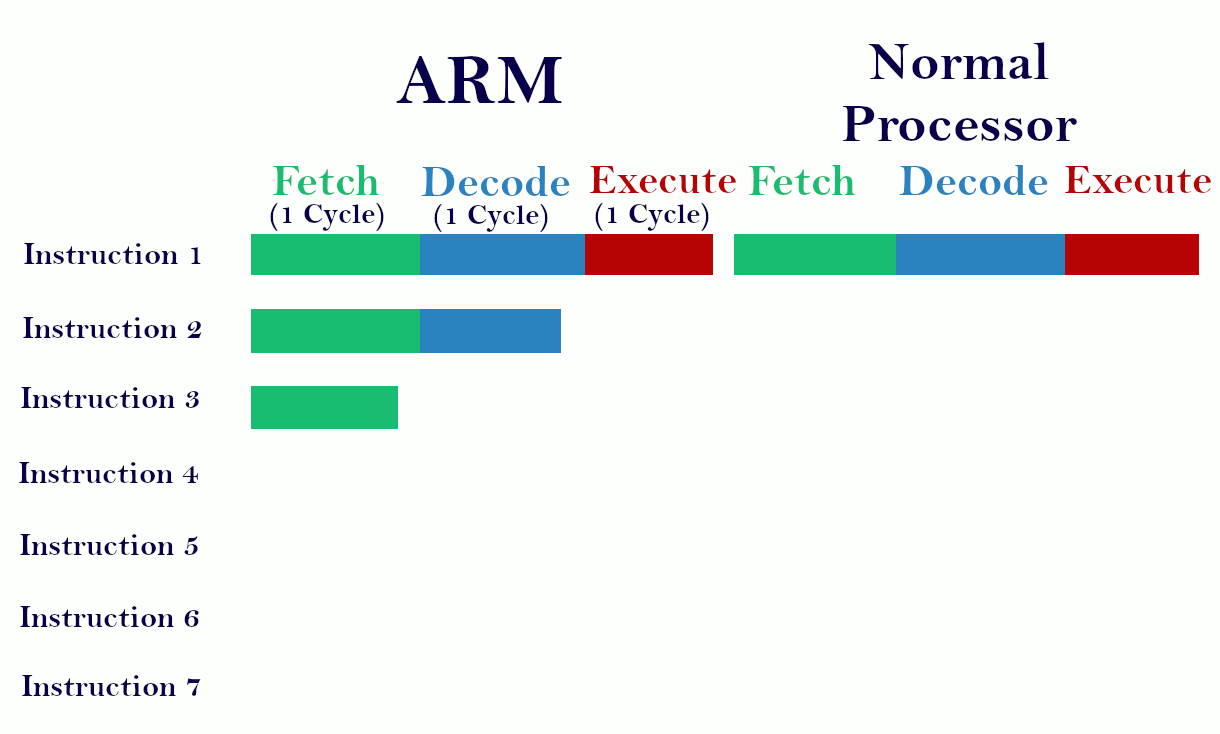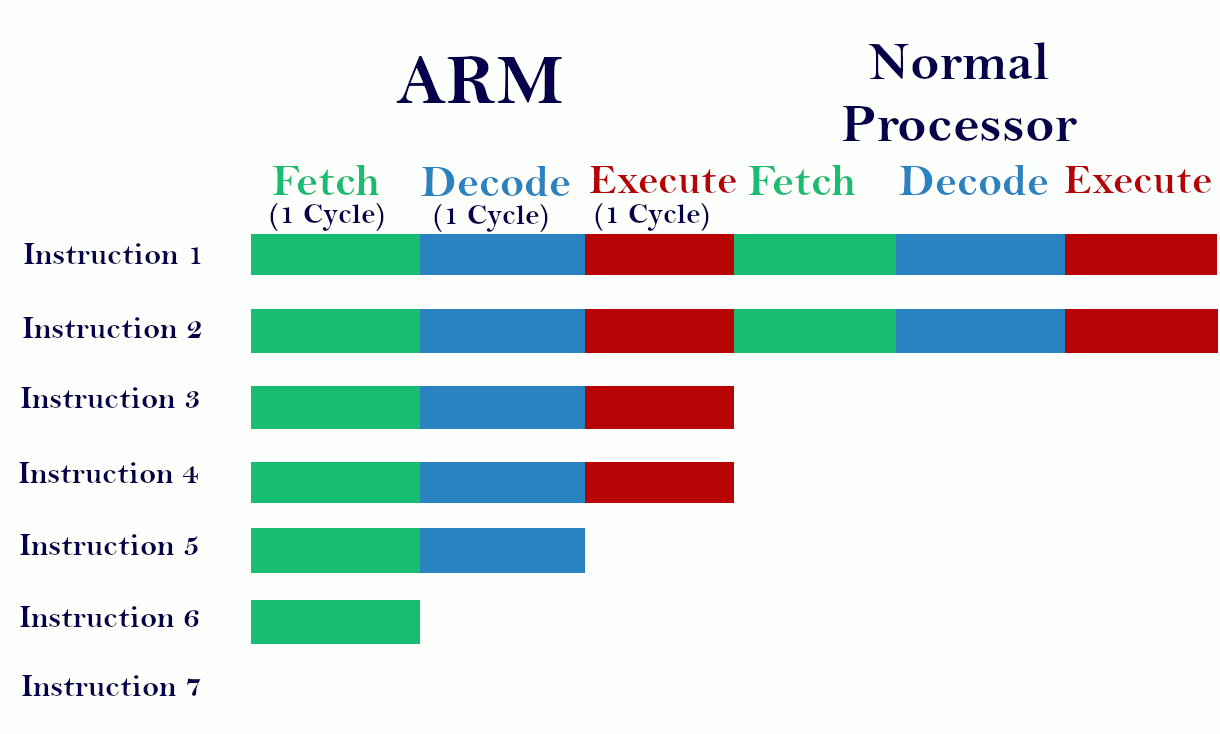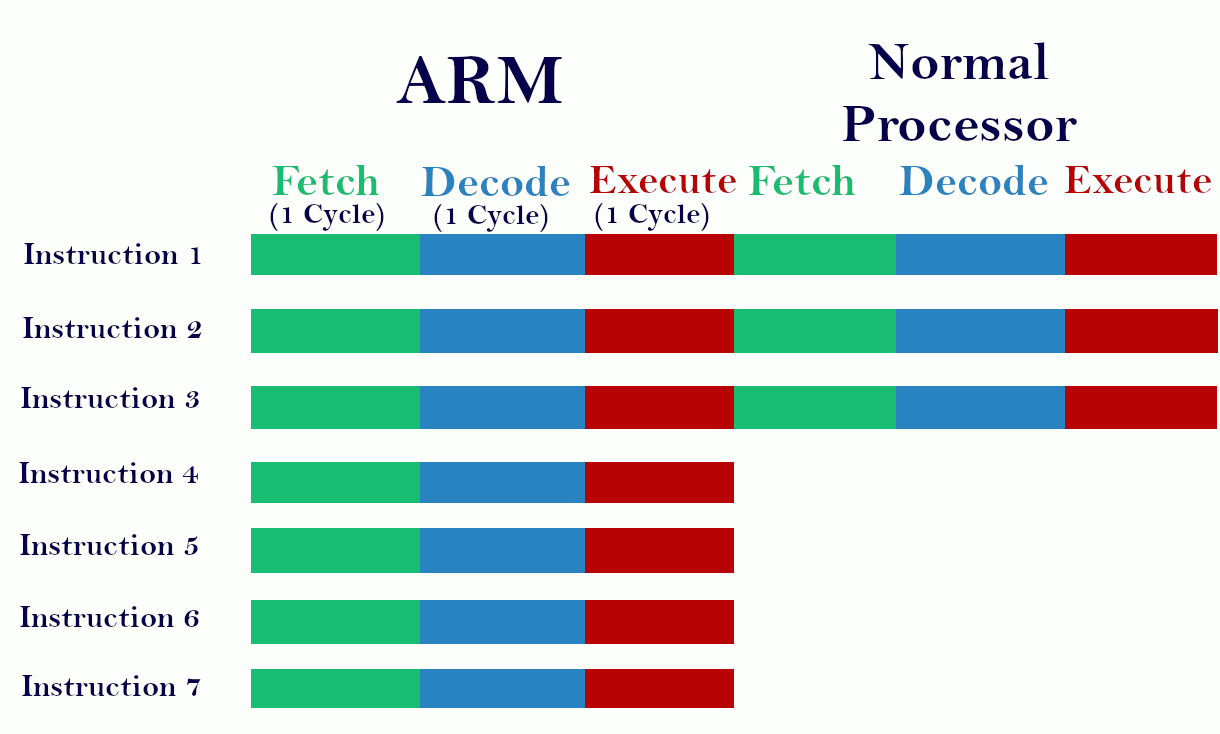
How does ARM acquire the Pipelining concept..?
It divides the total work complete to 3 independent parts (fetch, decode, execute) and overlap them.
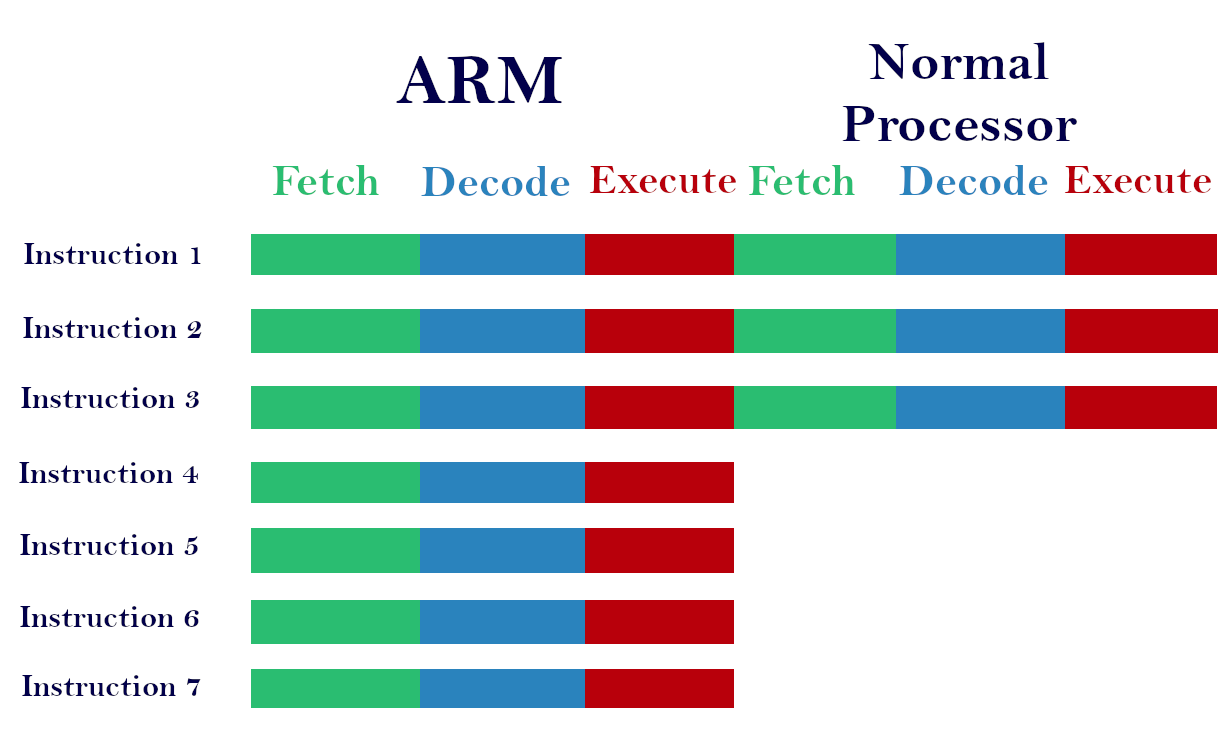
Fetch the first instruction in one cycle, then decode the fetching instruction and fetch the next instruction in one cycle. Now execute the decoded instruction and decode the fetching instruction in one cycle and also fetch the 3rd instruction in the same cycle. It is only possible when each of the three only needs one cycle for its operation. Then only we can fetch, decode, and execute 3 different instructions in one cycle. It gives better performance. On the above diagram, you can see the ARM process seven instructions where normal processor executes only 3.

The concept of the Pipeline only gives efficiency when all independent jobs (fetching, decoding, and executing) are done at the same time (1 cycle). Suppose there are 3 instructions, only the second instruction needs 2 cycles to decode. When the execution of first instruction will finish, the decode of second instruction is supposed to finish, but it requires one more cycle to fully decode for which that stage not able to execute the second instruction.
That's why ARM supports almost all instructions that require only one cycle to fetch, decode, and execute. And am going to prove that all these stages require only one cycle.
Fetching:- Instruction sets of ARM are 32 bit. And the most important is everything in ARM memory is in aligned form. Databus is also 32 bit. So Everything needs only 1 cycle to fetch.
Decoding:- ARM is a RISC processor. All instructions are reduced and simplified. Upcodes are simple. They are decoded using the hardwired control unit which is very fast. Hence the decode needs only one cycle.
Execution:- ARM supports memory-based operation only load and store. Load means getting data. The size of the data can be 32 bit(maximum). The data bus is 32 bit. So load requires one cycle. All arithmetic and logical operations happen on the register. Registers are 32-bit Operations are 32 bit and ALU is 32 bit. So every operation requires one cycle. Store means to store the data of register to memory through the data bus. All registers are 32 bit and the data bus is also 32 bit. so the store also requires one cycle. Hence all kinds of execution require only one cycle to execute.
Of course, there are one or two exceptions like multi-load and multi-store that require more than one cycle. But we can say 95% of ARM instructions are required one cycle for fetching, one cycle for decoding, and one cycle for executing. If anything takes more time then the 3 times multiplication performance will not happen.
Also, Read👇




{kind=link}